Dva pravila za AI poslovanje (i startupe koji ih ignoriraju)
Da parafraziram Andrewove riječi s njegovog tečaja na Courseri o dubokom učenju:
Trud koji je potreban za prepolovljavanje stope pogrešaka AI sustava je sličan, bez obzira na početnu stopu pogrešaka.
Ovo nije baš intuitivno. Ako AI sustav točno riješi 90% testnih slučajeva i pogriješi u 10%, znači li to da ste završili 90% posla? Popravite preostalih 10% pogrešaka i imat ćete stopostotnu točnost? Apsolutno ne.
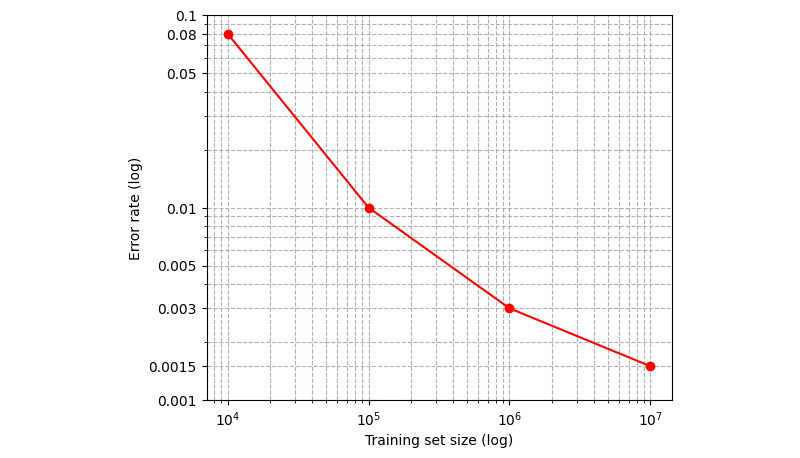
Ako vam je trebalo šest mjeseci da prepolovite stopu pogreške s 20% na 10%, trebat će vam otprilike još šest mjeseci da prepolovite 10% na 5%. I još šest mjeseci da prepolovite 5% na 2,5%. I tako u beskonačnost. Nikada nećete postići stopu pogrešaka od 0% u stvarnom AI sustavu. Za ilustraciju, pogledajte ovaj tipičan grafikon stope pogrešaka u odnosu na broj uzoraka za treniranje:

Primijetite da kasnije u procesu treniranja veličina seta za treniranje eksponencijalno raste sa svakim prepolovljenjem stope pogrešaka, a stopa pogrešaka nikada ne doseže nulu. Naravno, postat ćete učinkovitiji u prikupljanju podataka za treniranje (npr. korištenjem manje kvalitetnih izvora ili sintetičkih podataka). Ipak, teško je vjerovati da će biti puno lakše prikupiti deset puta više podataka nego početni set.
Zakon padajućih prinosa kod AI-ja
Ovo pravilo postaje intuitivnije kada se raščlani što predstavlja stopa pogrešaka AI sustava. To su svi poznati posebni slučajevi u stvarnom svijetu. A njih ima beskonačno. Na primjer, jedan od najlakših zadataka u strojnom učenju (ML) je klasifikacija slika pasa i mačaka. To je uvodni zadatak s online tutorijalima koji postižu 99% točnosti. Ali rješavanje preostalih 1% nevjerojatno je teško. Na primjer, je li stvorenje na ovoj fotki pas ili mačka?
Riječ je o mački imena Atchoum, koja postala je slavna jer je pola ljudi prepoznaje kao – psa. Ljudska točnost u klasifikaciji pasa/mačaka unutar 30 sekundi je 99,6%. Klasifikator pasa/mačaka sa stopom pogrešaka manjom od 0,4% bio bi nadljudski. Ali i to je moguće. Skup podataka sa stotinama tisuća pasa i mačaka neobičnog izgleda mogao bi naučiti neuronsku mrežu da se fokusira samo na detalje kodirane u kromosomima psa ili mačke (npr. mačje oči). Međutim, izrada takvog skupa podataka poprilično je složenija od tutorijala s 99% točnosti.
Ima i drugih problema koji se kriju u tih 1% stope pogrešaka: fotografije koje su previše tamne, fotografije u niskoj rezoluciji, artefakti kompresije fotografija, postprocesiranje fotografija na pametnim telefonima (dodavanje nepostojećih detalja), psi i mačke s medicinskim stanjima itd. Problema ima beskonačno. No, ovo se i dalje smatra riješenim ML problemom jer je stopa pogrešaka od 1% dovoljna za sve praktične svrhe.
Ali za neke probleme čak ni stopa pogrešaka od 0,01% nije zadovoljavajuća. Poput potpunog samostalnog upravljanja vozilom (FSD). Elon Musk je 2015. godine za Forbes rekao:
Imat ćemo s potpunu autonomiju i mislim da ćemo je imati za otprilike dvije godine.
Bili su toliko sigurni u to predviđanje da je 2016. godine Tesla počela prodavati dodatni paket za potpuno samostalno upravljanje. Tesla nije bila usamljena u tome. Kyle Vogt, izvršni direktor Cruisea, napisao je članak “Kako smo izgradili prvi pravi autonomni automobil (stvarno)” 2017. godine u kojem je tvrdio:
Najkritičniji zahtjev za masovnu primjenu je zapravo sposobnost proizvodnje automobila koji pokreću taj softver.
Dakle, softver i radni prototip su gotovi; samo trebaju proizvesti “100.000 vozila godišnje”.
Ako pogledamo situaciju 2024. godine, Muskova predviđanja za autonomna Teslina vozila zaslužila su poduži popis na Wikipediji, uglavnom u crvenom:

A što je s Kyleom Vogtom? U listopadu 2023. godine, Cruiseov automobil vukao je pješaka 6 metara, nakon čega je kalifornijski odjel za motorna vozila suspendirao Cruiseovu licencu za autonomni taksi. Kyle je “podnio ostavku” na mjesto izvršnog direktora u studenom 2023.
Tema je to koja je aktualna i u Hrvatskoj, tako još uvijek raspravljamo što je koja razina autonomije.
Nemojte me krivo shvatiti — vjerujem da će autonomni automobili imati značajan tržišni udio, vjerojatno u sljedećem desetljeću. Neuspješna predviđanja gore ilustriraju što se događa kada poduzetnici ne poštuju zakon padajućih prinosa kod AI-ja. Elon i Kyle vjerojatno su vidjeli demo potpuno autonomnog automobila koji je mogao voziti sam, po sunčanom danu, po označenoj cesti. Naravno, vozač zadužen sigurnost trebao je ponekad intervenirati, ali to je bilo samo 1% vremena vožnje.
Lako je zaključiti da je “autonomna vožnja riješen problem”, kako je Elon rekao 2016. godine. No, primijetite kako znanstvenici i inženjeri iz područja ML-a nisu davali takve bombastične izjave. Bili su svjesni mnogih rubnih slučajeva, od kojih su mnogi opisani u izvješćima o nesrećama.
Primjeri rubnih slučajeva su:
- Pješak koji gura bicikl preko dvotračne avenije po noći i bez svjetla (Uberova nesreća iz 2018.).
- Bijele rubne linije koje se razdvajaju prije barijere (nesreća Tesla Modela X iz 2018.).
- Bijela prikolica kamiona ispred bijelog neba (nesreća iz 2019., Tesla Model 3 obezglavila vozača i nastavila voziti 40 sekundi).
- Vozilo koje udara pješaka ispod FSD automobila (gore spomenuti incident s Cruiseom iz 2023.).
Zašto su mnoge tvrtke obećale drastično smanjenje stopa pogrešaka autonomne vožnje u tako kratkom roku bez potpuno nove ML arhitekture, ostaje kao otvoreno pitanje. Zakoni skaliranja za konvolucijske neuronske mreže poznati su već neko vrijeme, a nove transformer arhitekture slijede sličan zakon skaliranja.
Pravilo AI-ja: Proizvod ili značajka
Kada je AI sustav dobar samostalan proizvod, a kada je samo značajka? Riječima Benedicta Evansa iz podcasta “The AI Summer”:
Je li ovo značajka ili proizvod? Pa, ako ne možete garantirati točnost, to je značajka. Koja treba biti omotana u nešto što upravlja ili kontrolira očekivanja.
Volim tu izjavu. I mislim da se dio “točnost” može specificirati korištenjem stope pogrešaka:
Ako vaš AI sustav ima višu stopu pogrešaka od ciljanih korisnika, imate AI značajku u postojećem radnom tijeku, a ne samostalan AI proizvod.
Ovo je pravilo intuitivnije od zakona padajućih prinosa. Ako su ciljani korisnici bolji u nekom zadatku, neće im se svidjeti rezultati samostalnog AI sustava. I dalje bi mogli koristiti AI kako bi uštedjeli trud i vrijeme, ali će htjeti pregledati i urediti AI rezultate. Ako AI potpuno zakaže u zadatku, ljudi će koristiti stari način rada i stari softver za dovršavanje zadatka.
Uzmimo za primjer Midjourney, koji generira cijele slike na temelju tekstualnog upita. Kada sam ga koristio za hobi projekt prošle godine, zadovoljavajuće slike pojavile su se odmah, poput magije. Ali onda sam proveo sate popravljajući ruke:

Svaki put kada bi Midjourney stvorio novu sliku, jedna od ruku imala je loše dijelove. Konačno, generirao je sliku s dvije normalne ruke — ali tada je uništio uši. Problem nije bio toliko u krivim detaljima, već u lošem korisničkom sučelju koje nije omogućilo ispravku AI pogrešaka.
Adobeov pristup je drugačiji — on tretira generativnu AI tehnologiju kao samo jednu značajku unutar svog paketa proizvoda. Možete koristiti postojeći alat, odabrati područje, a zatim napraviti generativno popunjavanje:

Možete ga koristiti za najmanje zadatke, poput uklanjanja opušaka cigareta s trave na fotografiji s vjenčanja. Ako vam se ne sviđa AI generirana trava, nema problema — vratite se starom dizajnerskom zadovoljstvu ručnog kloniranja trave. Također, Adobe Illustrator ima generativni vektorski AI koji generira vektorske oblike koje možete urediti po svojoj želji.
Midjourney pravi impresivnije demonstracije, ali Adobeov pristup korisniji je za profesionalne dizajnere. To ne znači da Midjourney nema smisla kao proizvod, njegovi su ciljani korisnici oni koji ne mare za detalje. Na primjer, prošlog Božića dobio sam sliku čestitke preko WhatsAppa:

Jeste li primijetili ruke i oči malog Isusa? Pogledajte još jednom:

To nikada ne bi prošlo kod dizajnera, ali to nije poanta. Postoji cijela svita korisnika kojima nije stalo do kompozicije slike i detalja, oni samo žele vizuale koji idu uz njihov sadržaj. Drugim riječima, Midjourney nije zamjena za Adobeov Creative Suite — on je zamjena za stock fotografije kakve možemo naći na Shutterstocku i Getty Imagesu. I sudeći po nedavnoj popularnosti AI generiranih slika na društvenim mrežama i webu, ljudi više vole umjetničke slike Midjourneyja nego stock slike.
Izvrsno područje za samostalne AI proizvode su slučajevi korištenja gdje visoka stopa pogrešaka nije bitna ili je još uvijek bolja od ljudske stope pogrešaka. Nesretan su primjer navođeni projektili. U Zaljevskom ratu, točnost Tomahawk raketa bila je manja od 60%. Ali vojska ih je rado kupovala jer, u usporedbi s njima, tek manje od 1 u 14 nenavođenih projektila pogađa ciljeve.
Evaluacija startupa na temelju gore navedenih pravila
Izvrsno je da su stope pogrešaka mjerljive, pa gornja pravila daju metodu za brzo procjenjivanje AI startupa. Ispod je jednostavan primjer.
Devin AI je napravio senzaciju u ožujku 2024. godine s video demo prikazom AI alata koji može stvoriti potpuno funkcionalne softverske projekte. U najavi je navedeno da je Devin bio “evaluiran na SWE-Bench” (relevantno mjerilo) i da “ispravno rješava 13,86% problema bez pomoći, što daleko nadmašuje prethodne najbolje modele (SOTA) koji rješavaju 1,96%. Dakle, trenutno najbolji model ima stopu pogrešaka od 98%, a oni tvrde da imaju stopu pogrešaka od 86%. Čak i ako je ta tvrdnja točna (nije neovisno potvrđena), zašto njihovi promotivni videi prikazuju uspjeh za uspjehom? Ispostavilo se da su video primjeri pažljivo odabrani, opisi zadataka su promijenjeni, a Devinu su trebali sati i sati da ih dovrši.
Po mom mišljenju, Microsoft je ispravno postupio s GitHub Copilotom. Iako LLM-ovi rade iznenađujuće dobro za kodiranje, još uvijek prave puno pogrešaka i nemaju smisla kao samostalan proizvod. Copilot je značajka integrirana u popularne IDE-ove koja se pojavljuje s prijedlozima kada su oni vjerojatno korisni. Možete pregledati, urediti ili poboljšati svaki prijedlog.
Opet, nemojte me krivo shvatiti. Mislim da će se SOTA kodiranja drastično poboljšati u idućim godinama i da će jednog dana AI moći riješiti 80% GitHub problema. Devin AI je još uvijek daleko od tog dana, iako tvrtka ima procijenjenu vrijednost od 2 milijarde dolara u 2024. godini.
Formalno, metoda za evaluaciju je:
- Pronađite relevantnu mjeru za specifičan slučaj korištenja AI-ja.
- Pronađite trenutnu najbolju stopu pogrešaka (SOTA) i ljudsku stopu pogrešaka na toj mjeri.
- Je li SOTA bolja ili usporediva s ljudskom stopom pogrešaka?
- Ako da (malo vjerojatno): Sjajno, problem je riješen i možete stvoriti samostalan AI proizvod reprodukcijom SOTA rezultata.
- Ako ne (vjerojatno): Razmislite postoji li segment kupaca koji je tolerantniji prema pogreškama. Ako postoji, još uvijek možete imati nišni samostalan proizvod. Ako ne možete pronaći takav segment, idite na sljedeći korak.
- Ne možete izdati samostalan AI proizvod? Pričekajte da se SOTA poboljša, uložite novac u istraživanje ili idite na sljedeći korak.
- Razmislite kako integrirati AI kao značajku u postojeći proizvod. Olakšajte korisnicima otkrivanje i ispravljanje AI pogrešaka. Zatim izmjerite povrat ulaganja u AI:
AI_ROI = Trud_ušteđen_točnim_AI_odgovorima / Trud_potrošen_na_provjeru_i_ispravljanje_AI_odgovora
Ako previše korisničkog vremena ide na provjeru i ispravljanje AI pogrešaka (AI_ROI <= 1), nemate čak ni značajku.
Ili, da sumiramo sve ovdje raspravljeno u jednoj rečenici:

Svaki inovativni slučaj upotrebe AI-ja će se na kraju pretvoriti u značajku ili proizvod, kada stope pogrešaka to dopuste. Ako želite da se to dogodi brže, postanite znanstvenik.
Rani zaposlenici OpenAI-ja proveli su sedam godina na AI istraživanju prije no što su “preko noći” postigli uspjeh s ChatGPT-om. Ilya Sutskever, glavni znanstvenik OpenAI-ja, i dalje nije htio objaviti ChatGPT 3,5 jer se bojao da previše “halucinira”. Znanost zahtijeva vrijeme.
Ako vam je ovaj članak bio koristan, podijelite ga.
pročitaj cijeli članak



?")
?")